LASSO 回归分析原理与R语言实现
Lasso(Least absolute shrinkage and selection operator)一种数据挖掘方法,可以在模型参数估计的同时实现变量(因素)的选择,较好的解决回归分析中的多重共线性问题,并且能够很好的解释结果。
一、LASSO简要介绍
随着科技的进步,收集数据的技术也有了很大的发展。因此如何有效地从数据中挖掘出有用的信息也越来越受到人们的关注。统计建模无疑是目前处理这一问题的最有效的手段之一。在模型建立之初,为了尽量减小因缺少重要自变量而出现的模型偏差,人们通常会选择尽可能多的自变量。但实际建模过程中通常需要寻找对响应变量最具有解释性的自变量子集—即模型选择(或称变量选择、特征选择),以提高模型的解释性和预测精度。所以模型选择在统计建模过程中是极其重要的问题。
Lasso(Least absolute shrinkage and selection operator, Tibshirani(1996))方法是一种压缩估计。它通过构造一个罚函数得到一个较为精炼的模型,使得它压缩一些系数,同时设定一些系数为零。因此保留了子集收缩的优点,是一种处理具有复共线性数据的有偏估计。
Lasso 的基本思想是在回归系数的绝对值之和小于一个常数的约束条件下,使残差平方和最小化,从而能够产生某些严格等于0 的回归系数,得到可以解释的模型。R的Lars 算法的软件包提供了Lasso编程,我们根据模型改进的需要,可以给出Lasso算法,并利用AIC准则和BIC准则给统计模型的变量做一个截断,进而达到降维的目的。因此,我们通过研究Lasso可以将其更好的应用到变量选择中去。
说简单点:在回归分析中因素筛选主要用到逐步回归stepwise、向前、向后等等方法,这些方法比较传统,而对于共线性问题比较严重的数据,或者变量个数大于观测值个数例如基因测序数据,基因个数远大于观测值个数(病人数),上述传统方法不合适,而Lasso 方法就是为了解决上述问题而生,它提供了一种新的变量筛选算法,可以很好的解决共线性问题,对于我们平常做的回归分析,如果大家觉得用普通的方法筛选到的变量不理想,自己想要的变量没有筛选到,可以用此方法试一试,具体流程是先在R软件中用此方法筛选出变量,之后对筛选出的变量再做COX回归或者其他回归分析。
二、为什么需要用 Lasso + Cox 生存分析模式一般我们在筛选影响患者预后的变量时,通常先进行单因素Cox分析筛选出关联的变量,然后构建多因素模型进一步确认变量与生存的关联是否独立。
但这种做法没有考虑到变量之间多重共线性的影响,有时候我们甚至会发现单因素和多因素Cox回归得到的风险比是矛盾的,这是变量之间多重共线性导致模型 失真的结果。并且,当变量个数大于样本量时(例如筛选影响预后的基因或突变位点,候选的变量数可能远超样本个数),此时传统的Cox回归的逐步回归、前 进法、后退法等变量筛选方法都不再适用。
因此,当变量之间存在多重共线性或者变量个数大于样本量时,需要用Lasso(Least absolute shrinkage and selection operator)回归首先进行变量的筛选,然后构建Cox回归模型分析预后影响,这就是Lasso + Cox 生存分析模式。
三、什么是 Lasso + Cox 生存分析模式Lasso可以在模型参数估计的同时实现变量的选择,能够较好的解决回归分析中的多重共线性问题,并且能够很好的解释结果。Lasso回归算法使用L1范数进行收缩惩罚,对一些对于因变量贡献不大的变量系数进行罚分矫正,将一些不太重要的变量的系数压缩为0,保留重要变量的系数大于0,以减少Cox回归中协变量的个数。
四、LASSO方法R语言实现
刚说过,Lasso主要是做变量选择,我们下面主要讲解下,在R中如何实现变量筛选。
刚说过,Lasso主要是做变量选择,我们下面主要讲解下,在R中如何实现变量筛选。

第一行和第二行:调用glmnet 和survival包;
第三行调用数据,数据格式与普通的spss中格式一样,一行代表一条观测,一列代表一个变量;
第四行在筛选变量前,首先将自变量数据转变成矩阵(matrix);
第五行,做cox回归的人都知道,在设置应变量,生存时间和生存状态;
第六行是最关键的一行,调用glmnet包中的glmnet函数,注意family那里一定要制定是“cox”,如果是做logistic需要换成"binomial"。
第七行代码是输出模型,一般情况下会给出soultion path,具体可以看出在每一步筛选到的变量;
第八行第九行,主要在做交叉验证;
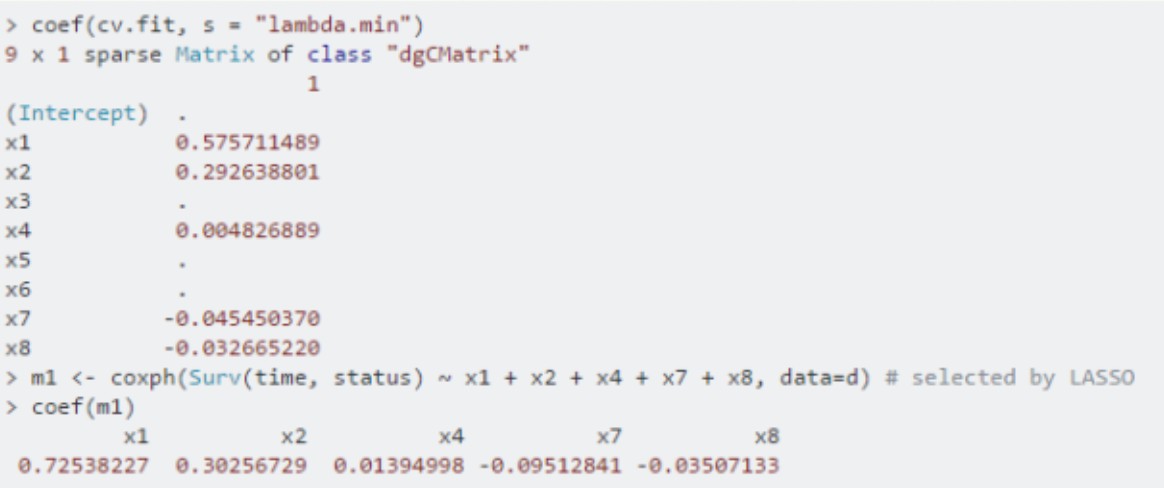
第十行代码是是挑选出CV最小时的lambda值,从结果可以看出筛选到的变量是x1,x2,x4,x7,x8;
第十一行是利用筛选到变量拟合cox回归模型;
第十二行是给出cox回归模型的系数;
- 发表于 2021-03-30 15:51
- 阅读 ( 15235 )
- 分类:基础知识
