刚接触高通量测序的时候就知道有链特异性建库这么个概念,当时也了解可以利用加U法,但是没有思考其中的细节。最近把这个概念掰开了揉碎了好好理解,终于填上了这个坑。
正式讲之前,有几个概念是要明确的。
DNA 的正链和负链,就是那两条反向互补的链。参考基因组给出的那个链就是所谓的正链(forword),另一条链是反链(reverse)。但是这正反一定不能和正义链(sense strand)反义链(antisense strand)混淆。
正义链(sense strand):两条互补的DNA链其中一条携带编码蛋白质信息的链称为正义链,又称编码链,因为它的序列与mRNA相同。
反义链(antisense strand):另一条与之互补的称为反义链。而反义链虽然和RNA反向互补,但它可是真正给RNA当模板的链,因此反义链也是模板链。
要注意的是:在一条包含有若干基因的双链DNA分子中,各个基因的正义链并不都是在同一条链上。
也就是说,有的基因的正义链是正链(forword strand),有的基因的正义链是反链(reverse strand)。所以,DNA双链中的一条链对某些基因来说是正义链,对另一些基因来说则是反义链
总结两点
正义链(sense strand)= 编码链(coding strand)= 非模板链
forword strand 上可以同时有sense strand 和 antisense strand。因为这完全是两个不同的概念
下面通过这张建库示意图来看看普通RNA-Seq建库和链特异性建库的差异在什么地方
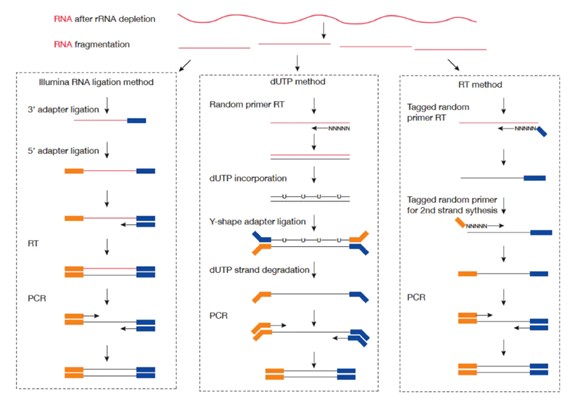
首先说说普通的RNA-Seq建库方式:它是在RNA逆转录成双链cDNA的两端,对称地加上了两个Y型的接头,然后变成文库。它有一个缺点,就是它是以双链DNA进行测序。所以测完序后,我们无法知道测出来的reads是来自正链还是负链。
而链特异性建库(以图中间的dUTP方法为例)则是首先利用随机引物合成RNA的一条cDNA链,在合成第二条链的时候用dUTP代替dTTP,加adaptor后用UDGase处理,将有U的第二条cDNA降解掉。降解发生之后,双链的文库就只剩下了一条链(负链)。而这条链的两头是接的不同序列的接头。通过PCR扩增,最终只保留了第一条cDNA(负链)上级测序。这样最后的insert DNA fragment都是来自于第一条cDNA(负链),也就是dUTP叫fr-firststrand的原因。在测序的过程中先测得正链reads,再测得负链reads(能区分正负链reads,这就是和普通建库最根本的不同)。在这些reads比对到参考基因组时,那些比对到基因方向(正义链方向)的正链reads就是正义链reads,但是那些比对到基因方向反方向(反义链方向)的正链reads就是反义链reads。那么同样,比对到基因方向的负链reads就是正义链reads,而比对到基因方向反方向(反义链方向)的负链reads就是反义链reads。从而最终将所有正义链reads和反义链reads区分开来。因此在确定基因表达水平时,可以避免基因反义链上的reads匹配的干扰,从而更加准确的检测基因转录表达水平。而且LncRNA的测序也离不开链特异性建库技术。原因有三:
1)lncRNA的来源是具有链特异性的;
2)lncRNA来源就是编码蛋白(mRNA)基因的反义链,是传说中的天然反义lncRNA(NAT-antisense lncRNA);如果是普通非链特异性建库,那么序列是来自mRNA,还是NAT-antisence LncRNA就难以区分了;
3)链特异性建库可更准确地统计转录本的数量和确定基因的结构,准确区分获得的转录本来自基因组哪条链。
链特异性文库参数设置: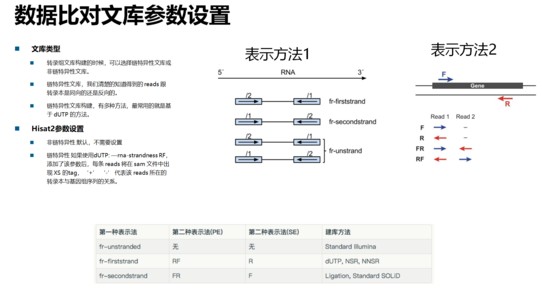 高级生物信息分析课程:重测序数据自主分析、二代测序转录组数据自主分析、微生物扩增子分析课程实操
高级生物信息分析课程:重测序数据自主分析、二代测序转录组数据自主分析、微生物扩增子分析课程实操
