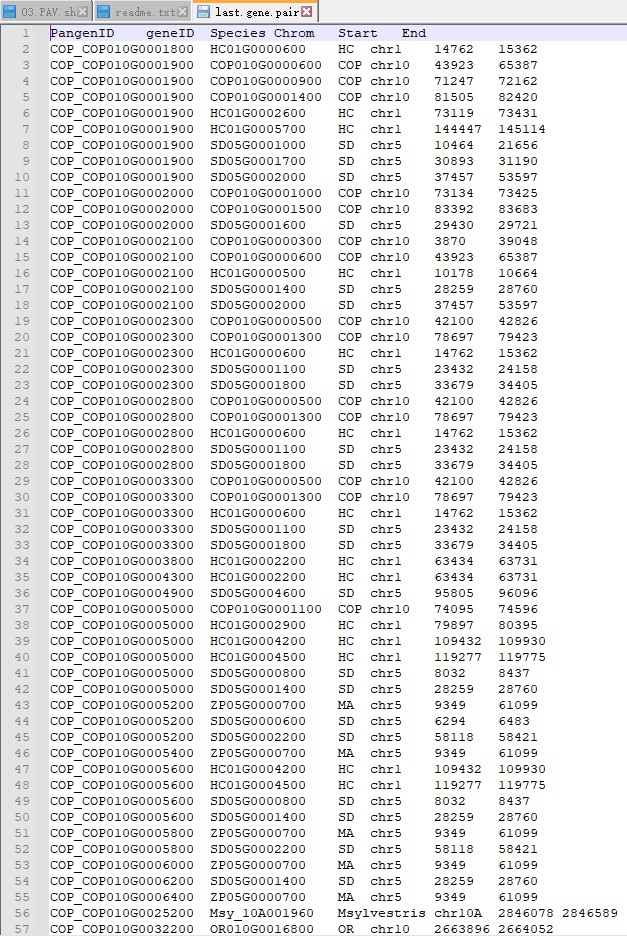
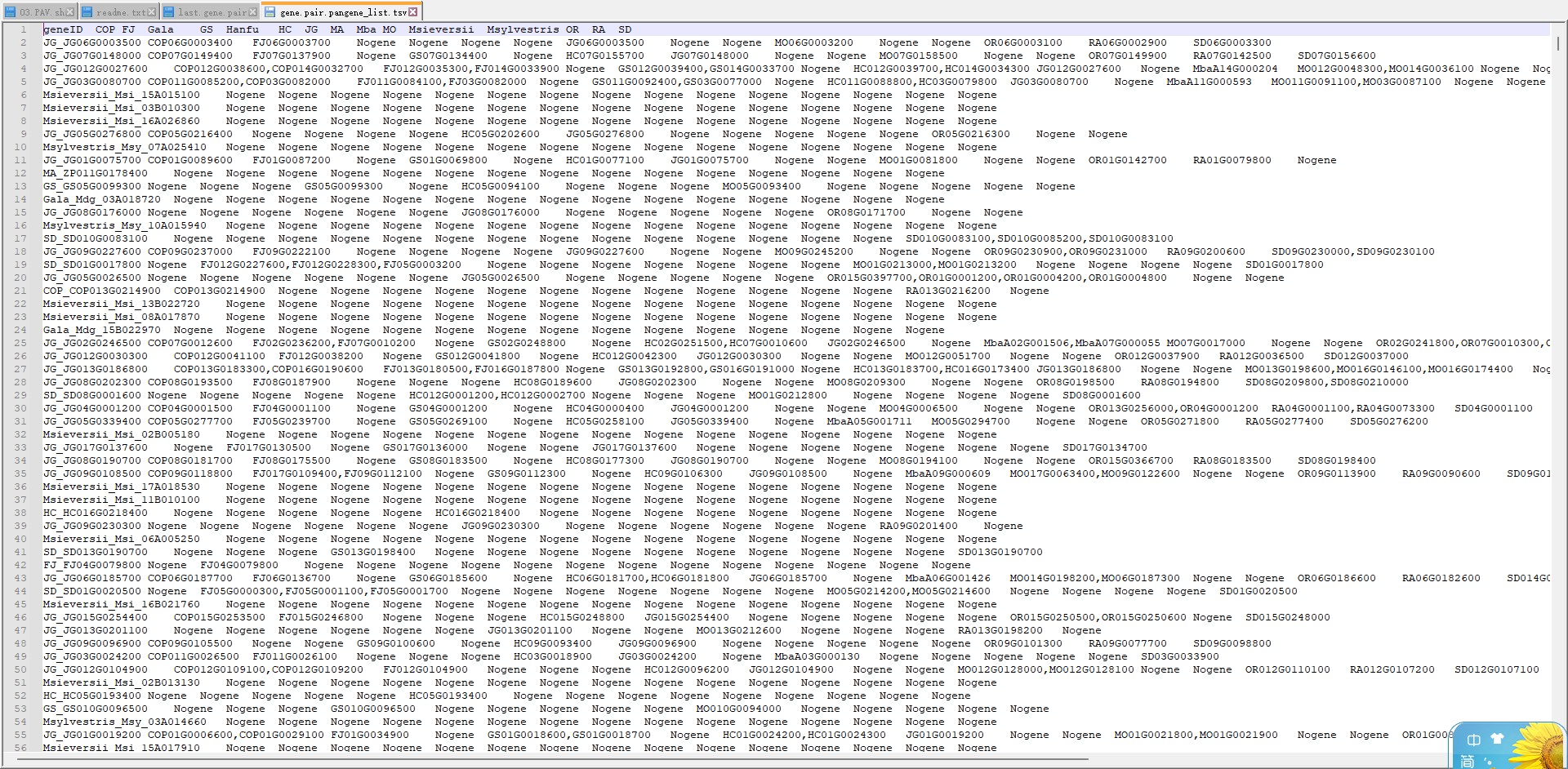
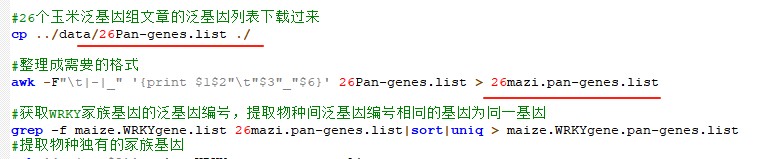
老师好,我正在进行PAV分析,公司帮我整理的这几个数据和shell中的数据对应不上,我应该怎么处理。具体问题如下:1.两个tsv文件有啥差异。2.shell中的26Pan-genes.list文件对应哪一个文件?是last.gene.pair文件,但是我看内容格式都不大一样。
第一个问题:项目结果文件有个readme文件,里面有每个文件的说明:表格pangene_list.tsv每一行是一个基因,及其对应不同基因组的基因ID,每一列是一个基因组。第二个问题:后续用来做泛基因家族分析需要用到的文件是*.gene.pair,该文件仅保留了有共线性关系的最佳匹配基因对。需要整理成后续脚本需要的格式。shell中的26Pan-genes.list文件是从文献中下载的,也是需要整理成后续脚本需要的格式。